1 Abstract¶
The IVOA SODA (Server-side Operations for Data Access) standard will be used to implement an image cutout service for the Rubin Science Platform following the requirements in LDM-554 4.2.3 and the architecture specified in DMTN-139 (not yet published). This document discusses implementation considerations and proposes an implementation strategy that uses Dramatiq as a work-queuing system, a pipeline task to perform the cutout, and Butler as the data store.
2 Implementation goals¶
This design satisfies the following high-level goals:
- Following SQuaRE’s standards for new web APIs, the web API layer should use FastAPI. This will satisfy the desired feature from DMTN-139 that each web service publish an OpenAPI v3 service description, since FastAPI does that automatically.
- There must be a clear division of responsibility between the service framework, which implements the IVOA API, and the data manipulation that produces the cutout. This is so that data manipulation is applied consistently in both Rubin data processing and VO services, and so that the service takes advantage of code validated as part of the science pipeline QA process.
- All locally-written software should be written in Python, as the preferred implementation language of the Rubin Observatory.
- The portions of the image cutout service that implement general IVOA standards, such as DALI and UWS components, will be designed to be separated into a library or framework and reused in future services. The implementation will also serve as a model from which we will derive a template for future IVOA API services.
3 Architecture summary¶
The image cutout service will be a FastAPI Python service running as a Kubernetes Deployment inside the Rubin Science Platform and, as with every other RSP service, using Gafaelfawr for authentication and authorization.
Image cutout requests will be dispatched via Dramatiq to worker processes created via a separate Kubernetes Deployment in the same cluster.
A high-availability Redis cluster will be used as the message bus and task result store for Dramatiq.
Image cutouts will be stored in a Butler collection alongside their associated metadata.
A request for the FITS file of the cutout will be served from that Butler collection.
Metadata about requests will be stored by the cutout workers in a SQL database, using CloudSQL for installations on Google Cloud Platform and an in-cluster PostgreSQL server elsewhere.
The same SQL store will be used by the API service to satisfy requests for async job lists, status, and other metadata.
The storage used by cutout results will be temporary and garbage-collected after some time. The expected lifetime is on the order of weeks. Users who wish to preserve the results for longer will need to transfer their data to a Butler collection in their own working space.
Here is the overall design in diagram form.
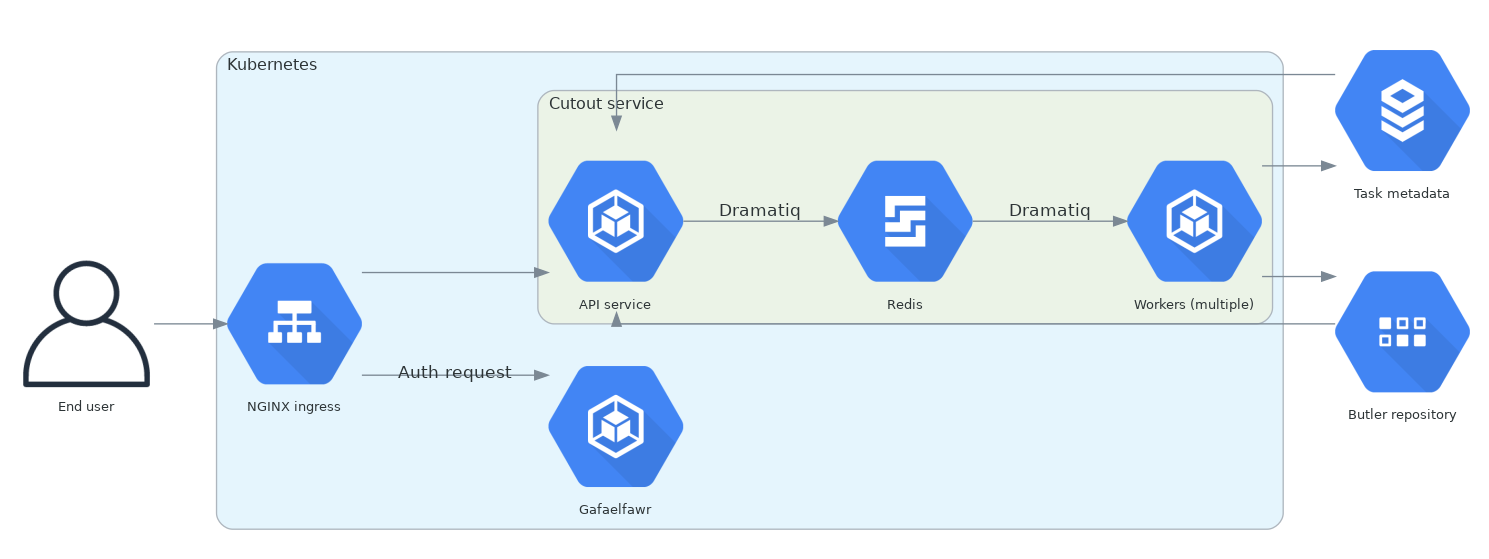
Figure 1 Image cutout service architecture
4 Performing the cutout¶
To ensure the cutout operation is performed by properly-vetted scientific code, the image cutout will be done via a pipeline task.
Currently, pipeline tasks must be invoked via the command line, but the expectation is that pipelines will add a way of invoking a task via a Python API. Once that is available, each cutout worker can be a long-running Python process that works through a queue of cutout requests, without paying the cost of loading Python libraries and preparing supporting resources for each cutout action.
The primary output of a cutout operation will be a FITS file.
A single cutout request may request multiple cutouts from the same source image.
In the language of the SODA specification, the cutout service permits only one ID parameter but allows multiple filtering parameters.
Each filtering parameter produces a separate cutout.
The cutouts will be returned as data in a single FITS file.
The first-specified cutout will be the Primary Array in the FITS file, and the additional cutouts will be included as additional HDUs.
5 Result format¶
The SODA specification supports two API modes: sync and async. A sync request performs and operation and returns the result directly. An async operation creates a pending job, which can then be configured and executed. While executing, a client can poll the job to see if it has completed. Once it has completed, the client can retrieve metadata about the job, including a list of reuslts, and then retrieve each result separately.
To avoid unnecessarily multipling API implementations, the sync mode will be implemented as a wrapper around the async mode using the implementation strategy described in the UWS specification. Specifically, a sync request will start an async job, redirect to a URL that blocks on the async job, and then redirects to the primary result URL for the async job.
The result of a sync request should be a FITS file. Therefore, the primary result of an async request will also be a FITS file. However, the true result of an async job will be a Butler collection including that FITS file plus associated metadata. Therefore, the full result list for the async job will be the FITS file (as the primary result) and the URL to the Butler collection holding the richer results. When client/server Butler is available, the primary result may be provided via a redirect to a Butler request to retrieve the FITS file from the collection. Until that time, it will be a redirect to an object store URL.
6 UWS implementation¶
The IVOA UWS (Universal Worker Service) standard describes the behavior of async IVOA interfaces. The image cutout service must have an async API to support operations that may take more than a few minutes to complete, and thus requires a UWS implementation to provide the relevant API. We will use that implementation to perform all cutout operations.
After a survey of available UWS implementations, we chose to write a new one on top of the Python Dramatiq distributed task queue.
6.1 Task result storage¶
An image cutout task produces two types of output: the cutouts themselves with their associated astronomical metadata, and the metadata about the request. The latter includes the parameters of the cutout request, the job status, and any error messages.
The task queuing system is the natural store for the task metadata. However, even with a configured result store, the task queuing system only stores task metadata while the task is running and for a short time afterwards. The intent of the task system is for the invoker of the task to ask for the results, at which point they are delivered and then discarded.
The internal result storage is also intended for small amounts of serializable data, not for full image cutouts. The natural data store for image cutouts is a Butler collection.
Therefore, each worker task will take responsibility for storing its own metadata, as well as the cutout results, in external storage. On success, the cutout results will be stored in a temporary Butler collection accessible only by the user requesting the cutout. On either success or failure, the task metadata (success or failure, any error message, and the request parameters) will be stored in a SQL database independent of the task queue system. If the task succeeded, the same metadata will also redundantly be stored in the output Butler collection so the collection has the provenance of the cutouts.
The image cutout web service will then use the SQL database to retrieve information about finished jobs, and ask the task queuing system for information about still-running jobs that have not yet stored their result metadata. This will satisfy the UWS API requirements.
The output Butler collections will be read-only for the user (to avoid potential conflicts with running tasks from users manipulating the collections) and will be retained for a limited period of time (to avoid unbounded storage requirements for cutouts that are no longer of interest). If the user who requested a cutout wishes to retain it, they should transfer the result Butler collection into their own or some other shared space. Alternately (and this is the expected usage pattern for sync requests and one-off exploratory requests), they can retrieve only the FITS file of the cutout and allow the full Butler collection to be automatically discarded later.
6.2 Summary of task queuing system survey¶
Since both the API frontend and the image cutout pipeline task will be written in Python, a Python UWS implementation is desirable. An implementation in a different language would require managing it as an additional stand-alone service that the API frontend would send jobs to, and then finding a way for it to execute Python code with those job parameters without access to Python libraries such as a Butler client. We therefore ruled out UWS implementations in languages other than Python.
dax_imgserv, the previous draft Rubin Observatory implementation of an image cutout service, which predates other design discussions discussed here, contains the skeleton of a Python UWS implementation built on Celery and Redis. However, job tracking was not yet implemented.
uws-api-server is a more complete UWS implementation that uses Kubernetes as the task execution system and as the state tracking repository for jobs.
This is a clever approach that minimizes the need for additional dependencies, but it requires creating a Kubernetes Job resource per processing task.
The resulting overhead of container creation is expected to be prohibitive for the performance and throughput constraints required for the image cutout service.
This implementation also requires a shared POSIX file system for storage of results, but we want to align the image cutout service with the project direction towards a client/server Butler and use Butler as the object store for results.
Finally, tracking of completed jobs in this approach is vulnerable to the vagaries of Kubernetes retention of metadata for completed jobs, which may not be sufficiently flexible for our needs.
We did not find any other re-usable Python UWS server implementations (as opposed to clients, of which there are several).
6.3 Task queue options¶
Celery is the standard Python task queuing system, so it was our default choice unless a different task queue system looked compelling. However, Dramatiq appeared to have some advantages over Celery, and there are multiple reports of other teams who have switched to Dramatiq from Celery due to instability issues and other frustration.
Both frameworks are similar, so switching between them if necessary should not be difficult. Compared to Celery, Dramatiq offers per-task prioritization without creating separate priority workers. We expect to do a lot of task prioritization to support sync requests, deprioritize expensive requests, throttle requests when the cluster is overloaded, and for other reasons, so this is appealing. Dramatiq is also smaller and simpler, which is always a minor advantage.
One possible concern with Dramatiq is that it’s a younger project primarily written by a single developer. Celery is the standard task queue system for Python, so it is likely to continue to be supported well into the future. There is some increased risk with Dramatiq that it will be abandoned and we will need to replace it later. However, it appears to have growing popularity and some major corporate users, which is reassuring. It should also not be too difficult to switch to Celery later if we need to.
Dramatiq supports either Redis, RabbitMQ, or Amazon SQS as the underlying message bus. Both Dramatiq and Celery prefer RabbitMQ and the Celery documentation warns that Redis can lose data in some unclean shutdown scenarios. However, we are already using Redis as a component of the Rubin Science Platform as a backing store for the authentication system, so we will use Redis as the message bus to avoid adding a new infrastructure component until this is shown to be a reliability issue.
Dramatiq supports either Redis or Memcache as a store for task results. Following the same principle, we will use Redis. (As discussed in 6.1 Task result storage, the task result will only be used for task metadata. The result of the cutout operation will be stored in the Butler, and the task metadata will separately be stored in a SQL database to satisfy the requirements for the UWS API.)