1 Abstract¶
The IVOA SODA (Server-side Operations for Data Access) standard will be used to implement an image cutout service for the Rubin Science Platform following the requirements in LDM-554 4.2.3 and the architecture specified in DMTN-139 (not yet published). This document discusses implementation considerations and describes the chosen implementation strategy, which uses Dramatiq as a work-queuing system and a separate dedicated GCS bucket as a result store.
See SQR-063 for additional discussion of difficulties with implementing the relevant IVOA standards.
2 Implementation goals¶
This design satisfies the following high-level goals:
Following SQuaRE’s standards for new web APIs, the web API layer should use FastAPI. This will satisfy the desired feature from DMTN-139 that each web service publish an OpenAPI v3 service description, since FastAPI does that automatically.
There must be a clear division of responsibility between the service framework, which implements the IVOA API, and the data manipulation that produces the cutout. This ensures that data manipulation is applied consistently in both Rubin data processing and VO services, and that the service takes advantage of code validated as part of the science pipeline QA process.
The worker processes that perform the data manipulation must be long-running so that the startup costs of loading relevant Python libraries and initializing external resources do not impact the performance of image cutout requests.
All locally-written software should be written in Python, as the preferred implementation language of the Rubin Observatory.
The service frontend must not require the full Rubin Observatory stack. This causes too many complications for building containers and coordinating Python package versions. Only the worker processes should require the stack, and should have a minimum of additional dependencies to limit how many Python modules we need to add to or layer on top of the stack.
The portions of the image cutout service that implement general IVOA standards, such as DALI and UWS components, will be designed to be separated into a library or framework and reused in future services. The implementation will also serve as a model from which we will derive a template for future IVOA API services.
Cutouts should be retrieved directly from the underlying data store that holds them, rather than retrieved and then re-sent by an intermediate web server. This avoids performance issues with the unnecessary middle hop and avoids having to implement such things as streaming or chunking in an intermediate server.
3 Architecture summary¶
The image cutout service will be a FastAPI Python service running as a Kubernetes Deployment inside the Rubin Science Platform and, as with every other RSP service, using Gafaelfawr for authentication and authorization.
Image cutout requests will be dispatched via Dramatiq to worker processes created via a separate Kubernetes Deployment in the same cluster.
Redis will be used as the message bus and temporary metadata result store for Dramatiq.
Image cutouts will be stored in a dedicated GCS bucket with an object expiration time set, so cutouts will be automatically purged after some period of time. The results of the cutout request will be served from that bucket.
The Dramatiq workers will be separated into two pools using different queues. One will perform the cutouts and will run on the stack container. The other, smaller pool will perform database housekeeping and store results or errors in the PostgreSQL database.
The storage used by cutout results will be temporary and garbage-collected after some time. The retention time for the initial implementation is 30 days, but this can easily be changed. Users who wish to preserve the results for longer will need to transfer their data elsewhere, such as local storage, their home directory on the Rubin Science Platform, or a personal Butler collection.
Metadata about requests will be stored by the cutout workers in a SQL database, using Cloud SQL for installations on Google Cloud Platform and an in-cluster PostgreSQL server elsewhere. The same SQL store will be used by the API service to satisfy requests for async job lists, status, and other metadata.
Here is the overall design in diagram form.
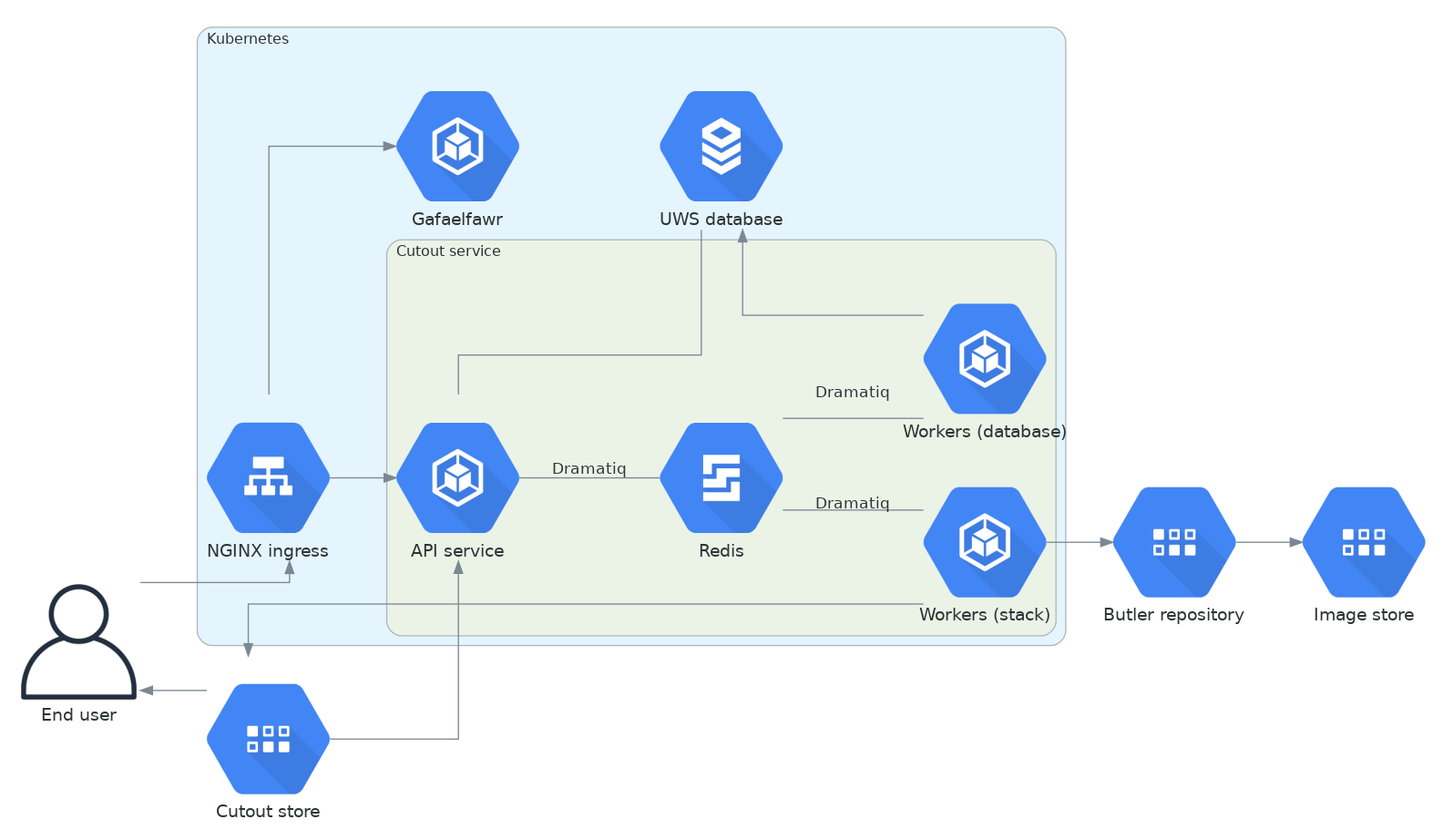
Figure 1 Image cutout service architecture¶
4 API service¶
The service frontend providing the SODA API will use the FastAPI framework.
The initial implementation won’t implement DALI-examples. This will be added in a later version.
4.1 Input parameters¶
SODA calls parameters that control the shape of the cutout “filtering parameters” or “filters.” The word filter is overloaded in astronomy, so this document instead calls those parameters “stencils.”
The initial implementation will support CIRCLE and POLYGON.
POS=RANGE and therefore POS support is more complex and will not be supported initially.
TIME and POL stencil parameters will not be supported.
BAND stencil parameters will not be supported in the initial implementation.
They may become meaningful later in cutout requests from all-sky coadds and can be added at that time.
The initial version of the cutout service will only support a single ID parameter and a single stencil parameter.
It is likely that we will support multiple stencils and multiple ID parameters in a future version of the service, but we may not use the API described in SODA for more complex operations, since its requirements for outputs and error reporting may not match our needs.
The ID parameter must be a UUID assigned by the Butler and uniquely identifying a source image.
The initial implementation will therefore only support cutouts from images that exist in a source Butler collection and thus have a UUID.
Virtual data products will not have a UUID because they will not already exist in a Butler collection, and therefore this ID scheme cannot be used to identify them.
The most natural way to identify a virtual data product is probably via the Butler data ID tuple.
When cutouts for virtual data products are later implemented, we expect those data products to be identified via a parameter (or set of parameters) other than ID, via an extension to the SODA protocol.
Those parameters would convey the Butler data ID tuple, and the ID parameter would not be used for such cutouts.
The initial implementation of the image cutout service will only return FITS files.
However, we expect to need support for other image types such as JPEG in the future.
When that support is added, it can be requested via a RESPONSEFORMAT=image/jpeg parameter.
The UWS specification supports providing a quote for how long an async query is expected to take before it is started.
The initial implementation will always set the quote to xsi:nil, indicating that it does not know how long the request will take.
However, hopefully a future improvement of the service will provide real quote values based on an estimate of the complexity of the cutout request, since this information would be useful for users deciding whether to make a complex cutout request.
The initial implementation will not support changing the job parameters after the creation of an async job but before the job is started. This may be added in a future version if it seems desirable.
4.2 API modes¶
The SODA specification supports two API modes: sync and async. A sync request performs and operation and returns the result directly. An async operation creates a pending job, which can then be configured and executed. While executing, a client can poll the job to see if it has completed. Once it has completed, the client can retrieve metadata about the job, including a list of results, and then retrieve each result separately.
To avoid unnecessarily multiplying API implementations, the sync mode will be implemented as a wrapper around the async mode. Specifically, a sync request will start an async job, wait for that job to complete, and then redirect to the primary result URL for the async job.
Further considerations for UWS support and async jobs are discussed in UWS implementation.
4.3 Permission model¶
For the stateful async protocol, all created jobs are associated with a user. Only that user has access to the jobs they create. Attempts to access jobs created by other users will return authorization errors.
In the initial implementation, there is no concept of an administrator role or special async API access for administrators. Administrators can directly inspect the database if needed, or can impersonate a user if necessary. Administrative access to the API without impersonation may be added in future versions if this proves useful.
Access control is done via Gafaelfawr.
Image cutout service access is controlled via the read:image scope.
The results of a cutout request will only be accessible by the user who requested the cutout. If that user wishes to share the results with others, they must download them and put them in some other data store that supports sharing.
4.4 Quotas and throttling¶
The initial implementation of the image cutout service will not support either quotas or throttling. However, we expect support for both will be required before the production launch of the Rubin Science Platform. Implementation in the image cutout service (and in any other part of the API Aspect of the Rubin Science Platform) depends on an implementation of a general quota service for the RSP that has not yet been designed or built.
Quotas will be implemented in the service API frontend. Usage information will be stored in the same SQL database used to store job metadata and used to make quota decisions.
Throttling will be implemented the same way, using the same data. Rather than rejecting the request as with a quota limit, throttled requests may be set to a lower priority when dispatched via Dramatiq so that they will be satisfied only after higher-priority requests are complete. If we develop a mechanism for estimating the cost of a request, throttling may also reject expensive requests while allowing simple requests.
If the service starts throttling, sync requests may not be satisfiable within a reasonable HTTP timeout interval. Therefore, depending on the severity of the throttling, the image cutout service may begin rejecting sync requests from a given user and requiring all requests be async.
All of these decisions will be made by the API service layer when the user attempts to start a new job or makes a sync request.
5 Performing the cutout¶
To ensure the cutout operation is performed by properly-vetted scientific code, the image cutout will be done via a separate package that uses the Rubin Observatory stack. Eventually, this package may also need to run pipeline tasks to support multi-step cutout operations, such as cutouts from PVIs that must be reconstructed from raw images. This is not required (or implemented) in the initial implementation.
The cutout backend is responsible for propagating provenance metadata from the source data and the cutout parameters into the resulting FITS file, or into appropriate metadata in the output files for other image types. See PipelineTask-level provenance in DMTN-185 for discussion of provenance metadata in general.
The cutout workers are long-running Python processes that work through queues of cutout requests, dispatching each to the code in the cutout backend. The same Butler instance and thus cached resources such as open database connections is used for the lifetime of the process. This avoids paying the cost of loading Python libraries and preparing supporting resources for each cutout action.
Once there is a client/server Butler service, Butler operations to perform the cutout will be done as the user requesting the cutout, using a delegated internal token as described in SQR-049. The mechanism to pass that delegated internal token from the API frontend to the cutout backend has not yet been designed.
5.1 Worker queue design¶
The worker processes run in a container built on top of the Rubin Observatory stack.
Once a job has been created via the frontend and queued, workers must perform the following actions:
Parse and store the input parameters in a format suitable for performing the cutout with a pipeline task.
Update the UWS job status to indicate execution is in progress.
Perform the cutout, storing the results in the output GCS bucket.
Update the UWS job status to indicate execution is complete and store a pointer to the file in the output GCS bucket.
If the cutout job failed, instead update the UWS job to indicate the job errored, and store the error message in the UWS database.
The simplest design would be to give the worker credentials for the UWS database and have it perform all of those actions directly, via a common UWS wrapper around an arbitrary worker process. However, the cutout work has to run on top of the stack, but the wrapper would need access to the database schema, the input parameter parser, and all of the resulting dependencies. This would require adding a significant amount of code on top of the stack container, which is not desirable for the reasons mentioned above. It may also uncover version conflicts between the Python libraries that are part of the stack and the Python libraries used by the other components of the cutout service.
A slightly more complex queuing structure can address this problem. Instead of a single cutout function (an “actor” in the Dramatiq vocabulary), define four actors (names given in parentheses):
The cutout actor itself, which takes a (JSON-serializable) list of arguments specifying the
IDand cutout stencil. (cutout)An actor that marks the UWS job as executing. (
job_started)An actor that marks the UWS job as complete and saves a pointer to the Butler output collection. (
job_completed)An actor that marks the UWS job as failed and saves the error message in the UWS database. (
job_failed)
The first actor will use the cutout queue.
The other three actors will use the uws queue.
Now, only the first actor needs to be run in a stack container.
The workflow looks like this:
Parse the input parameters in the frontend, determine the specific cutout actor to run, and pass them as a JSON-serializable list of arguments to the cutout actor. Include the job ID as a parameter.
As part of that message, set
on_successandon_failureDramatiq callbacks pointing tojob_completeandjob_failed, respectively.As its first action, the cutout actor sends a message to
job_startwith the job ID and timestamp.When the cutout actor finishes, either
job_completeorjob_failedwill be called automatically.
Then, run two pools of workers.
One is configured to only watch the cutout queue and is the one that does the actual work.
These workers will run on a stack container.
The other, smaller pool of workers will only watch the uws queue and do database housekeeping.
With this separation, the frontend and uws queue workers can share code, including the database schema, but only need a stub for the cutout actor.
Similarly, the cutout actor only needs to contain the code for performing the cutout, and can contain only stubs for the job_start, job_complete, and job_failed actors.
The Dramatiq result store will be used to pass the metadata for the cutout result from the cutout actor to the job_complete actor, and any exceptions from the cutout actor to the job_failed actor.
Note that this queuing design means that the database updates may be done out of order. For example, the job may be marked completed and its completion time and results stored, and then slightly later its start time may be recorded. This may under some circumstances be visible to a user querying the job metadata. We don’t expect this to cause significant issues.
5.2 Worker containers¶
Given this worker queue design, the worker container can be a generic stack container 1 plus the following:
- 1
Currently, the backend code for performing the cutout is not part of a generic stack container. However, the intent is to add it to
lsst-distrib. See `RFC-828 <https://jira.lsstcorp.org/browse/RFC-828`__.
The results of
pip install dramatiq[redis], so that the worker can talk to the message queue and result store.The code for performing the cutout. This is expected to be a single (short) file that performs any necessary setup for the pipeline task.
This container will be built alongside the container for the frontend and database workers.
5.3 Interface contract¶
This is the interface contract with the pipelines that will perform cutouts.
This is sufficient for the initial implementation, which only supports a single cutout stencil on a single ID parameter.
We expect to add multiple ID parameters and possibly multiple cutout stencils in future revisions of the service.
Also see DM-32097.
5.3.1 Input¶
An
ID, as a string, which is a UUID for aDatasetRefof a source image stored in the Butler. This must match the ID returned by ObsTAP queries, SIA, etc. The requirements for the image cutout service specify thatIDmay refer to a raw, PVI, compressed-PVI, diffim, or coadded image, but for this initial implementation virtual data products are not supported.A single cutout stencil. There are three possible stencil types:
Circle, specified as an Astropy SkyCoord in ICRS for the center and an Astropy Angle for the radius.
Polygon, specified as an Astropy SkyCoord containing a sequence of at least three vertices in ICRS. The line from the last vertex to the first vertex is implicit. Vertices must be ordered such that the polygon winding direction is counter-clockwise (when viewed from the origin toward the sky), but the frontend doesn’t know how to check this so the backend may need to.
Range, specified as a pair of minimum and maximum ra values and a pair of minimum and maximum dec values, in ICRS, as doubles. The minimums may be
-Infand/or the maximums may be+Infto indicate an unbounded range extending to the boundaries of the image. Range will not be supported in the initial implementation.
The GCS bucket into which to store the resulting cutout.
The long-term goal is to have some number of image cutout backends that are busily performing cutouts as fast as they can, since we expect this to be a popular service with a high traffic volume. Therefore, as much as possible, we want to do setup work in advance so that each cutout will be faster. For example, we want cutouts to be done in a long-running process that pays the cost of importing a bunch of Python libraries just once during startup, not for each cutout.
5.3.2 Output¶
The output cutout should be a FITS image stored in the provided GCS bucket. In the initial implementation, the backend produces only a FITS image. Future versions may create other files, such as a metadata file for that image. The cutout backend will return the path of the newly-stored files.
The FITS file should contain metadata recording the input parameters, time at which the cutout was performed, and any other desirable provenance information. (This can be postponed to a later revision of the pipeline.)
5.3.3 Errors¶
A cutout area that’s not fully contained within the specified image is an error (except for unbounded ranges).
The current SODA standard requires that this error be handled by returning success to the async job but setting the result to a text/plain document starting with an error code.
This seems highly unexpected and undesirable, so we will not be following that approach.
Instead, the operation should abort with an error if the cutout area is not fully contained in the specified image.
Errors can be delivered in whatever form is easiest as long as the frontend can recover the details of the error. (For example, an exception is fine as long as the user-helpful details of the error are in the exception.)
5.3.4 Future work¶
We expect to add support for specifying the output image format and thus request a JPEG image (or whatever else makes sense).
In the future, we will probably support multiple ID parameters and possibly multiple stencils.
When supported, the semantics of multiple ID values and multiple stencils are combinatorial: in other words, the requested output is one cutout for each combination of ID and stencil.
So two ID values and a set of stencils consisting of two circles and one polygon would produce six cutouts: two circles and one polygon on both of the two ID values.
For cutouts with multiple ID parameters or multiple stencils, there is some controversy currently over whether to return a single FITS file with HDUs for each cutout, or to return N separate FITS files.
The current SODA standard requires the latter, but we had thought the former would be easier to work with.
Because of this and the error handling problem discussed above, we may deviate from the SODA image cutout standard and define our own SODA operations that returns a single FITS file with improved error handling.
We will eventually need to support cutouts from virtual data products, which will not have UUIDs because they won’t already be stored in the Butler.
A natural way of specifying such data products is the Butler data ID tuple.
When we add support for such cutouts, we expect to use a different input parameter or parameters to specify them, as an extension to the SODA protocol, rather than using ID.
We may wish to support RANGE stencils in order to provide a more complete implementation of the SODA standard.
6 Results¶
6.1 Result format¶
All cutout requests will create a FITS file. A cutout request may also create additional output files if alternate image types are requested. It may also create a separate metadata file.
The job representation for a successful async request in the initial implementation will be a single FITS file.
The cutout image will be stored as an extension in the FITS file, not in the Basic FITS HDU.
This output should use a Content-Type of application/fits 2.
- 2
image/fitsis not appropriate since no image is returned in the primary HDU.
Therefore the sync API will redirect to the FITS file result of the underlying async job.
As discussed in 5.3.4 Future work, there is some controversy over the output format when multiple ID parameters or stencils are provided.
The initial implementation will not support this.
The FITS file will be provided to the user via a signed link for the location of the FITS file in the cutout object store. Signed URLs are temporary and are expected to have a lifetime shorter than the cutout object store, so the image cutout service will generate new signed URLs each time the job results are requested (possibly with caching of up to an hour). The URL of the job result may therefore change, although the underlying objects will stay the same, and the client should not save the URL for much later use. The same will be done for alternate image output formats when those are supported.
The SQL database that holds metadata about async jobs will hold the S3 URL to the objects in the cutout object store. That information will be retrieved from there by the API service and used to construct the UWS job status response.
Because the image will be retrieved directly from the underlying object store, the Content-Type metadata for files downloaded directly by the user must be correct in the object store.
The current plan is to have ButlerURI automatically set the Content-Type based on the file extension, and ensure that files stored in a output Butler collection have appropriate extensions.
6.1.1 Alternate image types¶
This section describes future work that will not be part of the initial implementation.
If another image type is requested, it will be returned alongside (not replacing) the FITS image. If another image type is requested and multiple cutouts are requested via multiple stencil parameters, each converted cutout will be a separate entry in the result list for the job. The converted images will be stored in the cutout object store alongside the FITS image.
If an alternate image type is requested, the order of results for the async job will list the converted images in the requested image type first, followed by the FITS file. As with the FITS file, the images will be returned via signed links to the underlying object store.
The response to a sync request specifying an alternate image type will be a redirect to an object store link for the converted image of that type. Sync requests that request an alternate image type must specify only one stencil parameter, since only one image can be returned via the sync API and the alternate image types we expect to support, unlike FITS, do not allow multiple images to be included in the same file. 3 This will be enforced by the service frontend.
- 3
The result of a sync request with multiple stencils and an alternate image type could instead be a collection (such as a ZIP file) holding multiple images. However, this would mean the output MIME type of a sync request would depend on the number of stencil parameters, which is ugly, and would introduce a new requirement for generating output collections that are not Butler collections. It is unlikely there will be a compelling need for a sync request for multiple cutouts with image conversion. That use case can use an async request instead.
6.2 Result storage¶
The output cutout object store will only retain files for a limited period of time (to avoid unbounded storage requirements for cutouts that are no longer of interest). The time at which the file will be deleted will be advertised in the UWS job metadata via the destruction time parameter. The object store will be read-only for the users of the cutout service.
If the user who requested a cutout wishes to retain it, they should store the outputs in local storage, their home directory in the Rubin Science Platform, a personal Butler collection, or some other suitable location.
The SODA specification also allows a request to specify a VOSpace location in which to store the results, but does not specify a protocol for making that request. The initial implementation of the image cutout service will not support this, but it may be considered in a future version.
7 UWS implementation¶
The IVOA UWS (Universal Worker Service) standard describes the behavior of async IVOA interfaces. The image cutout service must have an async API to support operations that may take more than a few minutes to complete, and thus requires a UWS implementation to provide the relevant API. We will use that implementation to perform all cutout operations.
After a survey of available UWS implementations, we chose to write a new one on top of the Python Dramatiq distributed task queue.
7.1 Task result storage¶
An image cutout task produces two types of output: the cutouts themselves with their associated astronomical metadata, and the metadata about the request. The latter includes the parameters of the cutout request, the job status, and any error messages.
The task queuing system would appear to be the natural store for the task metadata. However, even with a configured result store, the task queuing system only stores task metadata while the task is running and for a short time afterwards. The intent of the task system is for the invoker of the task to ask for the results, at which point they are delivered and then discarded.
The internal result storage is also intended for small amounts of serializable data, not for full image cutouts. The natural data store for image cutouts is an object store.
Therefore, each worker task will take responsibility for storing the cutout results in an external storage store. We will use the system described in 5.1 Worker queue design to route the pointer to that external storage to an actor that will update the UWS database with appropriate results.
The task metadata (success or failure, any error message, the request parameters, and the other metadata for a job required by the UWS specification) will be stored in a SQL database external to the task queue system. The parameters known before job execution (such as the request parameters) will be stored by the frontend. The other data will be stored by specialized Dramatiq actors via callbacks triggered by the success or failure of the cutout actor. The image cutout web service will then use the SQL database to retrieve information about finished jobs, and ask the task queuing system for information about still-running jobs that have not yet stored their result metadata. This will satisfy the UWS API requirements.
We will use Dramatiq result storage, but only to pass the metadata for the result files from the cutout actor to the actor that will store that in the database.
7.2 Waiting for job completion¶
Ideally, we should be able to use the task queuing system to know when a job completes and thus to implement the sync API and the UWS requirement for long-polling. Unfortunately, this is complex to do given the queuing strategy used to separate the cutout worker from the database work. A job is not complete from the user’s perspective until the results are stored, but the result storage is done by a separate queued task after the cutout task has completed. Waiting for the cutout task completion is therefore not sufficient to know that the entire job has completed from the user’s perspective.
In addition, UWS requires the server responding to a long-poll request to distinguish between the QUEUED and EXECUTING job states, but the move from QUEUED to EXECUTING does not trigger message bus activity for the cutout task (it’s handled by a separate subtask).
For the initial implementation, we will therefore support the sync API and long polling by polling the database for job status with exponential back-off. It should be possible to do better than this using the message bus underlying the task queuing system, but a message bus approach will be more complex, so we will hold off on implementation until we know whether the complexity is warranted.
7.3 Summary of task queuing system survey¶
Since both the API frontend and the image cutout pipeline task will be written in Python, a Python UWS implementation is desirable. An implementation in a different language would require managing it as an additional stand-alone service that the API frontend would send jobs to, and then finding a way for it to execute Python code with those job parameters without access to Python libraries such as a Butler client. We therefore ruled out UWS implementations in languages other than Python.
dax_imgserv, the previous draft Rubin Observatory implementation of an image cutout service, which predates other design discussions discussed here, contains the skeleton of a Python UWS implementation built on Celery and Redis. However, job tracking was not yet implemented.
uws-api-server is a more complete UWS implementation that uses Kubernetes as the task execution system and as the state tracking repository for jobs.
This is a clever approach that minimizes the need for additional dependencies, but it requires creating a Kubernetes Job resource per processing task.
The resulting overhead of container creation is expected to be prohibitive for the performance and throughput constraints required for the image cutout service.
This implementation also requires a shared POSIX file system for storage of results, but an object store that supports automatic object expiration is a more natural choice for time-bounded cutout storage and for objects that must be returned via a REST API.
Finally, tracking of completed jobs in this approach is vulnerable to the vagaries of Kubernetes retention of metadata for completed jobs, which may not be sufficiently flexible for our needs.
We did not find any other re-usable Python UWS server implementations (as opposed to clients, of which there are several).
7.4 Task queue options¶
Celery is the standard Python task queuing system, so it was our default choice unless a different task queue system looked compelling. However, Dramatiq appeared to have some advantages over Celery, and there are multiple reports of other teams who have switched to Dramatiq from Celery due to instability issues and other frustration.
Both frameworks are similar, so switching between them if necessary should not be difficult. Compared to Celery, Dramatiq offers per-task prioritization without creating separate priority workers. We expect to do a lot of task prioritization to support sync requests, deprioritize expensive requests, throttle requests when the cluster is overloaded, and for other reasons, so this is appealing. Dramatiq is also smaller and simpler, which is always a minor advantage.
One possible concern with Dramatiq is that it’s a younger project primarily written by a single developer. Celery is the standard task queue system for Python, so it is likely to continue to be supported well into the future. There is some increased risk with Dramatiq that it will be abandoned and we will need to replace it later. However, it appears to have growing popularity and some major corporate users, which is reassuring. It should also not be too difficult to switch to Celery later if we need to.
Dramatiq supports either Redis, RabbitMQ, or Amazon SQS as the underlying message bus. Both Dramatiq and Celery prefer RabbitMQ and the Celery documentation warns that Redis can lose data in some unclean shutdown scenarios. However, we are already using Redis as a component of the Rubin Science Platform as a backing store for the authentication system, so we will use Redis as the message bus to avoid adding a new infrastructure component until this is shown to be a reliability issue.
Dramatiq supports either Redis or Memcache as a store for task results. We only need very temporary task result storage to handle storing job results in the database, and are already using Redis for the message bus, so we will use Redis for task result storage as well.
Neither Celery nor Dramatiq support asyncio natively.
Dramatiq is unlikely to add support since the maintainer is not a fan of asyncio.
For the time being, we’ll enqueue tasks synchronously.
Redis should be extremely fast under normal circumstances, so this hopefully won’t cause problems.
If it does, we can consider other options, such as the asgiref.sync_to_async decorator.
After completing the initial implementation using Dramatiq, we briefly looked at arq, which has the substantial advantage of supporting asyncio.
However, arq does not support success and failure callbacks for tasks, which the current architecture relies on.
It should be possible to use arq by manually queuing the success and failure tasks from inside the cutout worker instead of relying on callbacks, so we may switch to arq in the future for the asyncio support.
7.5 Aborting jobs¶
In the initial implementation, we won’t support aborting jobs.
Posting PHASE=ABORT to the job phase URL will therefore return a 303 redirect to the job URL but will not change the phase.
(The UWS spec appears to require this behavior.)
In a later version of the service, we will use dramatiq-abort or the equivalent arq support to implement this feature.
8 Discovery¶
The not-yet-written IVOA Registry service for the API Aspect of the Rubin Science Platform is out of scope for this document, except to note that the image cutout service will be registered there as a SODA service once the Registry service exists.
The identifiers returned in the obs_publisher_did column from ObsTAP queries in the Rubin Science Platform must be usable as ID parameter values for the image cutout service.
In the short term, the result of ObsTAP queries will contain DataLink service descriptors for the image cutout service as a SODA service. Similar service descriptors will be added to the results of SIA queries once the SIA service has been written. This follows the pattern described in section 4.1 of the SODA specification.
In the longer term, we may instead run a DataLink service and reference it in the access_url column of ObsTAP queries or via a DataLink “service descriptor” following section 4.2 of the SODA specification.